Introducing the Neuroexplicit Models Blog
Written by Ji-Ung Lee
Published on 14th November 2025
Abstract: Neuroexplicit models are a type of machine learning model that combines deep learning with explicit AI; allowing them to utilize the generalization capabilities of deep neural models and at the same time, to exploit human-understandable, explicit components. Neurosymbolic models are the most prominent, but by far not the sole kind of neuroexplicit models. In this blog post, we will draw an outline of neuroexplicit models and by doing so, provide a new perspective on taxonomizing the increasing number of AI models.
Motivation
Over the last decade, deep learning has reached remarkable heights – we have seen AI models beating professional Go and Starcraft players 1 2 or generating breathtakingly realistic images.3 This was made possible by continuously scaling deep neural models with improving hardware and more data; resulting in models with remarkable generalization capabilities across tasks and domains, and ultimately allowing lay users to casually interact with models via natural language (without any prior knowledge).
Although these models continue to amaze us with all the tasks they seemingly solve, the increasing user base has also exposed numerous problems and dangers before they could even be adequately addressed. This has resulted in models being removed after premature deployment and showing biases with respect to gender and race or hallucinating incorrect facts.4 While increasingly sophisticated safety mechanisms are being developed, they often lack any guarantees, allowing malicious parties to jailbreak these models to abuse them, for instance, to generate misinformation and deep fakes 5. Combating these problems poses an increasing challenge to society as more capable and larger models continue to be released and as new regulations add more and more legal requirements such as the human interpretability of model predictions.6
In this Research Training Group, we investigate a class of models that have the potential to inherently address the above issues, so-called neuroexplicit models. These models combine both neural and explicit components in order to overcome their individual weaknesses and, at the same time, synergize their strengths. The most prominent kind of neuroexplicit models are neurosymbolic ones that combine neural architectures with symbolic components.7 However, we find various works that go beyond combining symbolic and neural approaches. One such example is the B-cos network (see below), a type of model that is fundamentally neural, but explicitly ties its prediction to parts of the input. Others propose to combine explicit inpainting methods based on partial differential equations together with neural networks,8 improving generalization to unseen real-world settings (something purely neural methods struggle with).
Types of neuroexplicit models
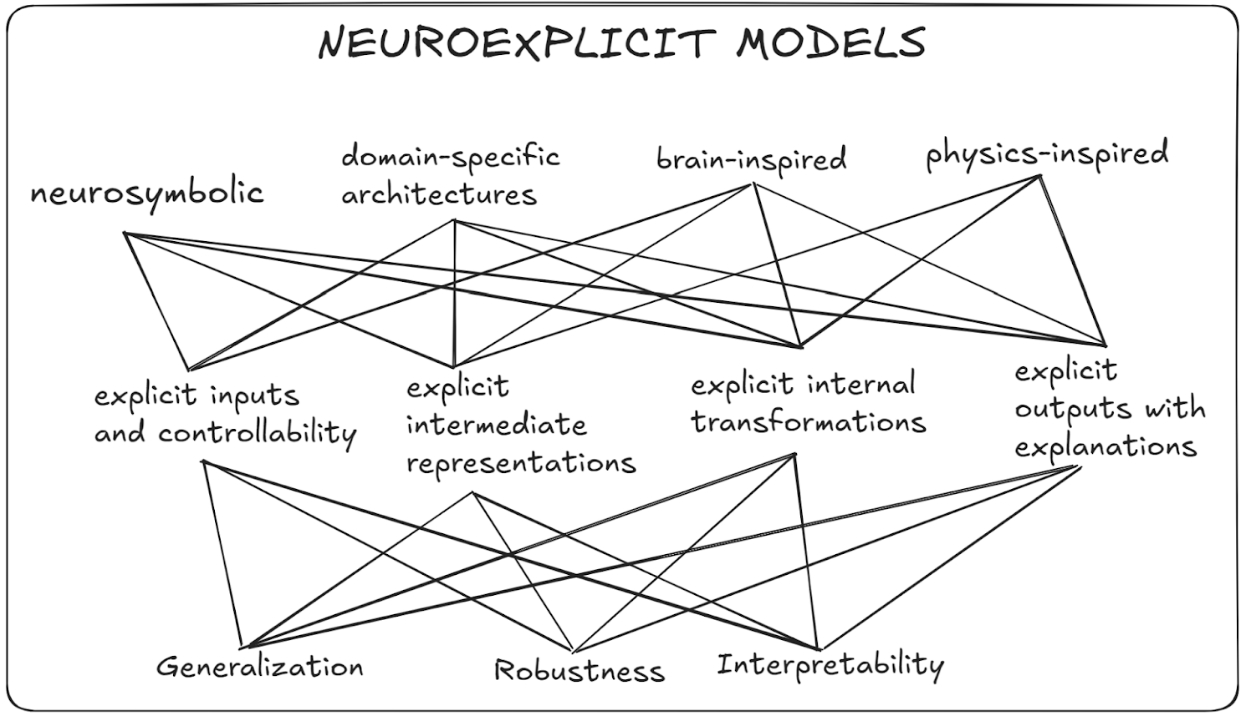
Figure 1 provides a broad overview about various existing neuroexplicit models and their strengths. First, they generalize in a way that is complementary to how purely neural models do thanks to their explicit components which are tied to specific concepts. Second, the explicit components inherently induce interpretability; for instance, via symbolic representations (e.g., logical expressions) or through structural representations (such as graphs). Third, the neural components allow the models to identify well-performing features through representation learning. Finally, both parts complement each other increasing the robustness of the resulting model – the explicit components increase robustness against noise or adversarial instances while the neural components can catch corner cases that would break the explicit model. Throughout this blog, we will categorize neuroexplicit models into three types:
- Models that are purely neural, but have been infused with explicit knowledge during training.
- Models that fuse neural and explicit models which have been trained individually.
- Models that are inherently neuroexplicit by design.

Model Training
Figure 2 shows a very straightforward way to infuse explicitness into neural models without changing the underlying architecture; i.e., by training them with structured data 9 or by utilizing an explicit model as an additional loss signal or environment.10 Especially in reinforcement learning scenarios where agents cannot be trained in a real-world setting, utilizing an explicit, physics-conformant simulation environment is key and has resulted in agents that are even capable of stabilizing the plasma in nuclear fusion reactors.11

One example of using training to obtain a neuroexplicit model is the work by Lindemann, Koller, and Titov who propose to infuse structural knowledge into Transformer-based models by utilizing explicit data.12 To do so, they propose an intermediate pre-training step where the Transformer is trained to perform syntactic transformations that are specified in the prefix of an input. During this step, the model is given a sentence and a set of edgewise transformations on a binarized syntax tree that describe the overall transformation. The model is then trained to predict how the transformation affects the respective syntax tree of the sentence. Afterwards, the model is fine-tuned on a downstream task. Figure 3 shows the full pipeline. In their experiments, the authors find that the additional pre-training step with structured data improves the model’s performance on tasks that require syntactic knowledge such as chunking, passivization, and others.
Advantages
As shown in the work by Lindemann et al 12, infusing explicitness into neural networks via training can substantially improve their performance on tasks that require structural knowledge. Besides, training models on explicit knowledge or structured data can make them less prone to hallucinations. Moreover, as the underlying architecture remains the same, we can keep utilizing existing methods such as quantization. Finally, these methods are straightforward to adapt to new models on a technical level, as they only require additional fine-tuning.
Disadvantages
While fine-tuning pre-trained models on structured data or explicit knowledge is often easier than training new models from scratch, the resulting models remain purely neural at their core. Hence, they do not provide any formal guarantees to adhere to hard constraints or to base their predictions on structures present in the data. Consequently, they may also remain unfaithful in terms of interpretability. Finally, it is not always given that the continued training of neural models using explicit knowledge will automatically lead to an improvement. Instead, the effects need to be evaluated on a per-model and per-task basis and additional measures might be necessary to stabilize training and prevent catastrophic forgetting.

Model Fusion
A second type of neuroexplicit model fuses existing neural and explicit components together into hybrid models (Figure 3). This can be achieved in various ways, for instance, by empowering neural models to make use of explicit components or by utilizing neural components in explicit models. Fusion methods can vary a lot and range from a static integration of explicit or neural components to fine-tuning them jointly in an end-to-end manner. One early example using LLMs was proposed in the Toolformer paper, where the authors empower the model to execute API calls by fine-tuning it on special tokens.13

A more recent example of fusing explicit and neural components has been proposed by Rao, Mahajan, Böhle, and Schiele in their work called Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery.14 In this work, the authors propose to utilize sparse-autoencoders together with a pre-trained neural model (CLIP3) to automatically discover and name task-agnostic concepts (see Figure 4). These are then used to train explicit concept-bottleneck models, resulting in performant and interpretable classifiers. A more detailed explanation of this approach will be provided in our follow-up blogpost.
Advantages
Neuroexplicit models that are derived by fusing neural and explicit components (such as concept-bottlenecks) can provide an inherent means of interpretability compared to purely neural models. Moreover, integrating the explicit components in a manner that preserves their pre-fusion guarantees can be of key importance; especially in critical application domains such as autonomous driving. Explicit components can also be used to improve the robustness of the resulting model, especially for (sub)tasks where neural models still struggle. Depending on the situation, fusion can also improve the computational efficiency, e.g., by replacing compute-intensive explicit parts with an approximative, but more efficient neural model.
Disadvantages
While fusing existing models can improve robustness, generalization, and interpretability via the introduction of formal guarantees, there are no default frameworks or interfaces for connecting explicit and neural components. Instead, identifying the right way to connect different components can vary across different models and domains. Moreover, integrating multiple, possibly conflicting components may result in unexpected interferences, leading to unstable training. More research is required to better understand how explicit and neural components interact with each other, especially when trained in a joint manner.

Model Design
Finally, there are works that propose new model architectures which inherently contain explicit and neural components (see Figure 4). Such models can be created for specific purposes, for instance, to explicitly capture graph structures15 or to increase computational efficiency.16

One example of a neuroexplicitly designed architecture are B-cos networks which are built to be inherently interpretable by ensuring that the output can faithfully be tied to a specific input.17 To achieve this, Böhle, Fritz, and Schiele propose to replace linear transforms with B-cos transforms that ensure weight-input alignment during optimization:
\[ \text{B-cos}(x;w) = \|\hat{w}\| \|x\| |c(w,\hat{w})|^{B} \times \text{sgn}(c (x,\hat{w})) \]Where \(\hat{w}\) is the scaled version of \(w\) with unit norm and \(\text{sgn}\) denotes the sign function. Although minimal, the proposed changes ensure that a) the output of B-cos neurons are bound, b) B can be used to control the degree of input-output alignment (see Figure 5 for an example), and c) sequences of B-cos transforms can still be faithfully summarized by a single linear transform. Their experiments show that B-cos models only incur minor drops in terms of classification accuracy compared to conventional neural networks, while being inherently interpretable.
Advantages
As shown with B-cos models, designing neuroexplicit models from scratch has the advantage that any required property such as inherently interpretability can be ensured by design. Note, that interpretability is not the only property for which models can be designed. For instance, neural ordinary differential equations can be used to conduct physical modeling.18 Other objectives may be to improve the run-time efficiency of specific components or to provide formal guarantees. Moreover, neuroexplicit models can also be designed to be more robust and to generalize better than purely neural models.
Disadvantages
Models that inherently possess specific properties have a huge advantage, however, it can be difficult to design models that possess multiple (possibly conflicting) properties at once. In addition, these models can have domain- or task-specific limitations one needs to be aware of. For instance, the linear time invariance of vanilla state-space models makes them unsuited for tasks that require associative recall and copying.19
Conclusion
In this blog post, we have made a first attempt to taxonomize neuroexplicit models and discussed their advantages as well as shortcomings. To do so, we introduced three general ways to obtain neuroexplicit models, i.e., by training, fusion, and design. Although these have been discussed separately in this blog post, we note that they are not necessarily fully separable. For instance, recent works on B-cos models have proposed b-cosification; i.e., turning pre-trained neural models into neuroexplicit ones by applying neuroexplicit design elements to them.20 21 Overall, we find that neuroexplicit models bear lots of potential to overcome existing issues with purely neural models, and that more research is necessary to identify well-suited use cases and to better understand their limitations. This will empower researchers and practitioners to make informed choices about which model to use. As this blog continues to develop along the research training group, we hope to provide a more in-depth and detailed understanding of neuroexplicit models.
References
-
Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” Nature (2016). ↩︎
-
Oriol Vinyals, Igor Babuschkin, Junyoung Chung, Michael Mathieu, Max Jaderberg, et al. 2019. “AlphaStar: Mastering the Real Time Strategy Game StarCraft II.” https://deepmind.com/blog/alphastar-mastering-real-time-strategy-game-starcraft-ii (2019). ↩︎
-
Radford, Alec, et al. “Learning transferable visual models from natural language supervision.” International conference on machine learning. PMLR (2021). ↩︎ ↩︎
-
Church K. “Emerging trends: When can users trust GPT, and when should they intervene?” Natural Language Engineering. Vol. 30(2):417-427. doi:10.1017/S135132492300057 (2024) ↩︎
-
Anwar, Usman, et al. Foundational Challenges in Assuring Alignment and Safety of Large Language Models. TMLR (2024). ↩︎
-
EU AI Act. ELI: http://data.europa.eu/eli/reg/2024/1689/oj ISSN 1977-0677 (2024) ↩︎
-
Mao, Jiayuan, Joshua B. Tenenbaum, and Jiajun Wu. “Neuro-Symbolic Concepts.” Communications of the ACM (2025). ↩︎
-
Tom Fischer, Pascal Peter, Joachim Weickert, and Eddy Ilg. “Neuroexplicit diffusion models for inpainting of optical flow fields”. ICML (2024). ↩︎
-
Banarescu, Laura, et al. “Abstract meaning representation for sembanking.” Proceedings of the 7th linguistic annotation workshop and interoperability with discourse. (2013). ↩︎
-
Tewari, Ayush, et al. “Mofa: Model-based deep convolutional face autoencoder for unsupervised monocular reconstruction.” IEEE international conference on computer vision workshops (2017). ↩︎
-
Degrave, Jonas, et al. “Magnetic control of tokamak plasmas through deep reinforcement learning.” Nature (2022). ↩︎
-
Lindemann, Matthias, et al. “Strengthening Structural Inductive Biases by Pre-training to Perform Syntactic Transformations”. EMNLP (2024). ↩︎ ↩︎
-
Schick, Timo, et al. “Toolformer: Language models can teach themselves to use tools.” NeurIPS (2024). ↩︎
-
Rao, Sukrut, Mahajan, Sweta et al. “Discover-then-Name: Task-Agnostic Concept Bottlenecks via Automated Concept Discovery” ECCV (2024). ↩︎
-
Yasunaga, Michihiro, et al. “Deep bidirectional language-knowledge graph pretraining.” NeurIPS (2022). ↩︎
-
Bengio, Emmanuel, et al. “Conditional computation in neural networks for faster models.” ICLR Workshop (2016). ↩︎
-
Moritz Böhle, Mario Fritz, and Bernt Schiele “B-cos networks: Alignment is all we need for interpretability” CVPR (2022). ↩︎
-
Kidger, Patrick. “On Neural Differential Equations.” PhD thesis (2022). ↩︎
-
Gu, Albert, and Tri Dao. “Mamba: Linear-time sequence modeling with selective state spaces.” arXiv:2312.00752 (2023). ↩︎
-
Shreyash, Arya, et al. “B-cosification: Transforming Deep Neural Networks to be Inherently Interpretable” NeurIPS (2024). ↩︎
-
Wang, Yifan, et al. “B-cos LM: Efficiently Transforming Pre-trained Language Models for Improved Explainability.” Arxiv (2025). ↩︎